Hanging around with red-black tree implementations: the beginnings
This last weekend I’ve spent my time taking a look one thing that I have in mind for several months ago, to implement a red-black tree data structure in several languages; obviously not all of them in two days, I usually try to sleep some hours a day ;D
The reason, which I came up with this idea, is because for more than one year I’ve been tinkering with several programming languages during part of my spare time, some, without exclusion, in personal projects, other in hackathons and others in courses; I’ve also read some amount of content, in some of them more than others, and in some of them I’ve only read, hence I’ve never got my hands dirty with those last few.
I know that it may not be the more funny activity to do in a weekend, however continue reading if you want to know why and what I’ve got so far, and what will be my path, and also, you may get the chance to see it’s not that boring.
Why I’ve chosen to implement a red-black tree
Well life is hard and trees solve a lot of problems, hahaha, I’m joking.
Why do I want to implement a red-black tree? being honest, I don’t have any preference rather than we had to implement one where I’m currently working, hence I could choose another data structure or even another type of tree, but that experience was the excuse to choose it.
That implementation was in javascript, concretely in NodeJS, basically because we needed to use in the environment where the component is running; moreover it was not a basic structure, it was targeting production, therefore it has to store and get the values from external sources; then it is difficult to follow easily the red-black tree algorithm and the focus of it is for the purpose to achieve; furthermore I didn’t almost do any part of the implementation, rather using it and implemented the stuff around, basically it means that I don’t discard to implement it in javascript in some point too, but I’m not very encouraged to do soon, as I regard to spend enough time with this programming language the most of the my days.
Why don’t I implement something useful for the humanity?
- First of all I should find something useful for the humanity that has not been implemented or has been but it can be, at least, improved in the most of the languages that now, I bear in mind to use.
- Secondly if I find it, I wouldn’t probably have the time to do the implementation for all of those, then I’ve simplified the problem to choose something quite small and academic (the most of the professional jobs never require to implement any tree or another data structure), however I don’t want to implement a “hello world!” so it’d be to copy and paste the examples of any language.
- Thirdly, I don’t want to implement a HTTP service, they are almost the same, they rely in using a library which does everything and you only have to write the route and it’s response based in the received request, moreover nowadays there may have enough on every language, hence it wasn’t going to provide anything useful for the humanity, anyway. I want to use some of the language properties, types, “structures” and so on, than one of its libraries or packages.
Then it won’t provide anything useful for the humanity.
are those implementations going to be for production/optimised? I don’t think so, this is a spare time toy, it means, I spend my free time doing this and also all other obligations, responsibilities, geek activities and human beings needs, then if the amount of time is already quite limited to implement those in basic and non-optimised way, and the probability to end with some of the languages implementations isn’t quite high, then I don’t think that I could achieve to do them in a well tested optimised way, that a production environment may need.
then, what may the implementations be? they’ll be the basic implementation of ta tree which contains nodes of integer key and values; continue reading to know a little bit more about this.
What I’ve got so far
Not that much. I’ve taken a look to the basic algorithm which drove me a c implementation and Java one which I haven’t taken a look so far.
I’ve decided to take the c one; sorry but I’ve fallen in love of the minimalist, nonetheless it doesn’t mean that I never skip it, if its opposite make sense because it simplify the solution and save time; nonetheless this is my spare time toy and I’ve preferred to take the c one and have some good remembers; obviously in the time being, I don’t think to do the c implementation, basically it will be the base.
Then I’ve downloaded it, I’ve created a basic makefile, and I compiled it and ran its test.
After that, I found that I had to generated some data which I can provide to the several future implementations; the c implementation that I’ve borrowed, it doesn’t read the data from any input source, its test auto-generate the random data which are inserted in the tree and after removed, to be able to test the implementation; therefore, I had to implement it to be able to test the same input and output data with the future implementations.
Then, I started the fun time, getting back to c after I don’t remember how many years I did wrote something, without taking in account the time that I spent in its big powerful but incontrollable brother (c++) but anyway it was long time ago.
At the end, I haven’t only implemented something that read a very basic input file to take integer pairs of keys and values (example of 25 pairs and more in this folder) but I’ve also implemented to generate the random pairs in the same binary (implemented in this main file) which create 3 output files, in the case that it’s been specified when it’s executed; one file is the pairs if they’ve been auto-generated (postfixed with -pairs.csv) when a number of pairs has been specified without no input file; another is the tree’s nodes (key, value and color) file (postfixed with -nodes.csv) in depth-first in-order traversal and the last one, the “visualisation” of a tree in a text file (postfixed with -tree.txt) which I’ve partly stolen from the test file of the taken implementation.
After I could test it and compare the results with this two visual representations of a red-black tree

corresponds to these files pairs, nodes and tree.
And this other
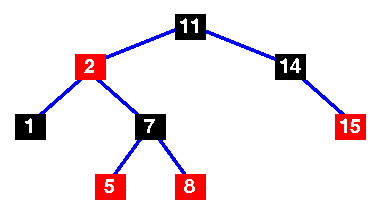
corresponds to these other files pairs, nodes and nodes.
And surprisingly you can see how the results that I’ve got from the c implementation are not equal to those visual examples, right? well, then if we take a look to the definition of red-back tree, we can read:
The balancing of the tree is not perfect but it is good enough to allow it to guarantee searching in O(log n) time, where n is the total number of elements in the tree.
so they’re not perfectly balanced, however the results are right, those fulfill the red-black tree properties.
you can also read this stack overflow question where somebody got the same issue, in another implementation, and have a better clarification.
What’s the next
I’ve already commented above, but let’s refresh it; my aim is to implement this data structure in several programming languages:
- Which one is the next? I don’t know for now, probably I’ll find out when I get the time which I encourage to spend on it, which will also define it.
- When? As I’ve just said, when I get a time that I encourage to do it.
- is this serious? Probably no, chill out dude, it’s my spare time, :P
To wrap up
I want to do a basic implementation of something, which I may achieve in terms of time, in some of the languages that I’ve been hacking around for more than one year; it’s a red-black tree data structure implementation.
what and when the first one == undefined
See you next week.